Entailment
Explainable Video Entailment with Grounded Visual Evidence
ICCV2021
[Paper],[Code],[Data]
Junwen Chen 1*, Yu Kong 1*
1ActionLab, *Rochester Institute of Technology
Abstract
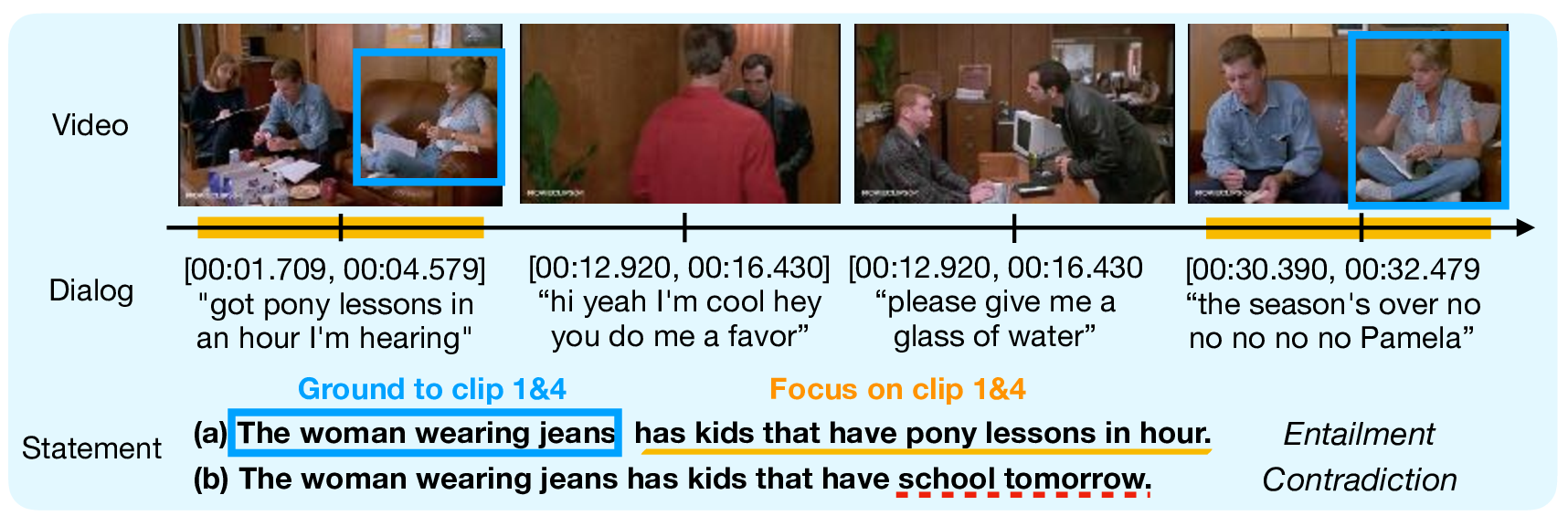
Video entailment aims at determining if a hypothesis textual statement is entailed or contradicted by a premise video. The main challenge of video entailment is that it requires fine-grained reasoning to understand the complex and long story-based videos. To this end, we propose to incorporate visual grounding to the entailment by explicitly linking the entities described in the statement to the evidence in the video. If the entities are grounded in the video, we enhance the entailment judgment by focusing on the frames where the entities occur. Besides, in the entailment dataset, the entailed/contradictory (also named as real/fake) statements are formed in pairs with the subtle discrepancy, which allows an add-on explanation module to predict which words or phrases make the statement contradictory to the video and regularize the training of the entailment judgment. Experimental results demonstrate that our approach outperforms the state-of-the-art methods.
Result Summary

|
If you find our work helpful to your research, please cite: |
|
@inproceedings{ChenICCV2021eve, |